Load Data Faster: ConnectorX - The Ultimate Data Loading Library for Python
Need a faster way to load data from your database into Python DataFrames? ConnectorX is a high-performance library that lets you load data from your database to DataFrames in Python faster and more efficiently.
![]()
What is ConnectorX?
ConnectorX is a library built in Rust, designed for speed and memory efficiency when transferring data from databases to dataframes. It supports destinations like Pandas and PyArrow. This makes it useful for data scientists, analysts, and engineers working with large datasets.
Key Benefits of Using ConnectorX
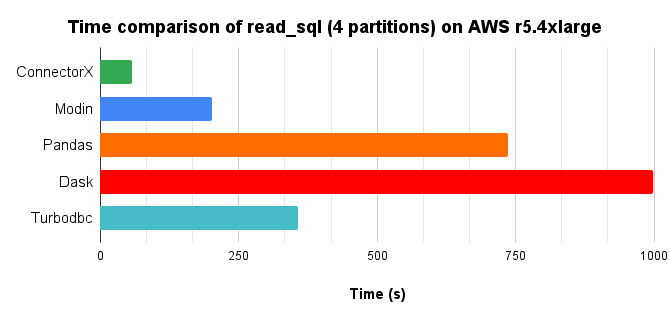
- Unmatched Speed: Load data up to 21x faster than other solutions, saving you valuable time.
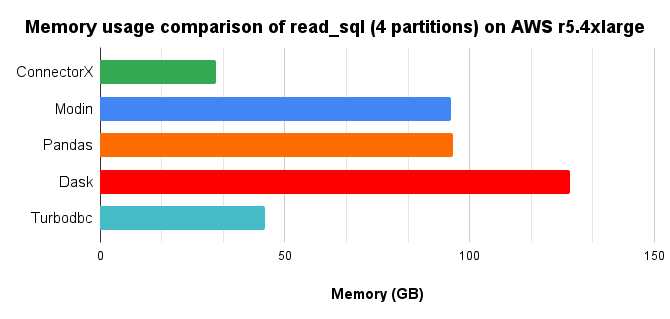
- Memory Efficiency: Uses 3x less memory, allowing you to work with larger datasets without memory issues.
- Easy to Use: Simple one-line code integration with Python.
- Parallelism: Accelerate data loading using parallelism by partitioning your data.
Get Started with ConnectorX
Installing ConnectorX is easy using pip:
pip install connectorx
Simple Example
Loading data with ConnectorX requires only one line of code:
Parallel Partitioning for Even Faster Loading
ConnectorX has partitioning the query by evenly splitting the specified column to the amount of partitions. Furthermore, ConnectorX assigns one thread for each partition to load and write data in parallel. However, you can also accelerate data loading using parallelism:
This will split the query into 10 partitions based on the l_orderkey column, enabling parallel data loading.
Performance Benchmarks: ConnectorX vs. Other Solutions
ConnectorX significantly outperforms other Python solutions for loading data from databases, as demonstrated by benchmarks loading a 10x TPC-H lineitem table (8.6GB) from Postgres into a DataFrame with 4 cores parallelism.
Time Comparison
Memory Consumption Comparison
How ConnectorX Achieves Lightning Speed
ConnectorX is written in Rust and follows a "zero-copy" principle. This minimizes data copying and maximizes CPU utilization. The architecture ensures data is copied exactly once, directly from the source to the destination.
How ConnectorX Downloads Data
- Schema Retrieval: ConnectorX first issues a
LIMIT 1query to get the schema of the result set. - Partitioning (Optional): If
partition_onis specified, ConnectorX determines the range of the partition column. - Query Splitting: The original query is split into partitions based on the min/max information.
- Count Query: ConnectorX runs a count query to get the partition size.
- Memory Allocation and Parallel Download: ConnectorX uses the schema and count information to allocate memory and download data in parallel, using one thread per partition.
Supported Data Sources and Destinations
ConnectorX supports a wide range of data sources and destinations:
Sources:

- PostgreSQL
- MySQL
- MariaDB
- SQLite
- Redshift
- ClickHouse
- SQL Server
- Oracle
- BigQuery
- Trino
- ODBC (WIP)
Destinations:

- Pandas
- PyArrow
- Modin (through Pandas)
- Dask (through Pandas)
- Polars (through PyArrow)
Integrations: ConnectorX and Polars for optimal data processing.
ConnectorX works very well with data processing frameworks such as Polars.
![]()
Resources for Further Learning
- Documentation: https://sfu-db.github.io/connector-x/intro.html
- Rust Docs: Stable | Nightly
- Developer's Guide: CONTRIBUTING.md
Contribute to ConnectorX
Get involved in the ConnectorX community! You can contribute by:
- Asking questions and proposing new ideas in the GitHub discussion forum.
- Answering questions on Stack Overflow with the tag #connectorx.
Projects Using ConnectorX
ConnectorX is used by various organizations and projects, including:
![]()

Citation
If you find ConnectorX useful in your research, please consider citing the following paper:
Xiaoying Wang, Weiyuan Wu, Jinze Wu, Yizhou Chen, Nick Zrymiak, Changbo Qu, Lampros Flokas, George Chow, Jiannan Wang, Tianzheng Wang, Eugene Wu, Qingqing Zhou. ConnectorX: Accelerating Data Loading From Databases to Dataframes. VLDB 2022.
Conclusion
ConnectorX is an essential tool for anyone working with databases and Python. Its speed, memory efficiency, and ease of use make it a must-have for data loading tasks. Start using ConnectorX today and experience the difference!








